
티스토리 뷰
Index
1. Selection Sort
2. Insertion Sort
3. Bubble Sort
4. Quick Sort
5. Merge Sort
6. Heap Sort
7. Radix Sort
1. Selection Sort (선택 정렬)
-
데이터를 처음부터 끝가지 훑어가면서 가장 작은 값을 찾아 그 값을 바꾼다.
-
각 루프마다 최소의 원소를 찾는다.
-
최소값을 맨 왼쪽(앞)의 원소와 교환한다.
-
맨 왼쪽 원소를 제외하고 하나의 원소가 남을 때까지 반복한다.

출처 : https://ko.wikipedia.org/wiki/%EC%84%A0%ED%83%9D_%EC%A0%95%EB%A0%AC*
-
시간복잡도 : O(n^2)
-
장점
- 데이터 양이 적을 때 좋은 성능을 낸다.
- 작은 갑슬 선택하기 위해서 비교는 여러번이지만 교환 횟수는 적다.
-
단점
- 시간복잡도가 O(n^2)라서 데이터가 많으면 느리다.
-
Code
public static void SelectionSort(int data[]) { int min; int tmp; for (int i = 0; i < data.length - 1; i++) { min = i; for (int j = i + 1; j < data.length; j++) { if (data[j] < data[min]) { min = j; } } if (data[min] < data[i]) { tmp = data[i]; data[i] = data[min]; data[min] = tmp; } } }
2. Insertion Sort
-
맨 처음 원소를 정렬되어있는 상태라고 보고, 그 다음 원소를 이 정렬된 배열에 삽입하면서, 두 개의 원소가 다시 정렬된 상태가 되도록 만드는 방법

https://ko.wikipedia.org/wiki/%EC%82%BD%EC%9E%85_%EC%A0%95%EB%A0%AC
-
시간복잡도 : O(n^2)
-
장점
- 대부분의 원소들이 정렬되어 있는 경우 효율적이다.
- 간단하다.
-
단점
- 원소들의 이동이 많아서 데이터가 클 경우 오래걸린다.
-
Code
public static void InsertionSort(int data[]) { int tmp; int j = 0; for (int i = 1; i < data.length; i++) { tmp = data[i]; for (j = i - 1; j >= 0 && data[j] > tmp; j--) { data[j + 1] = data[j]; } data[j + 1] = tmp; } }
3. Bubble Sort
-
서로 인접한 두 원소를 검사하여 정렬하는 알고리즘으로 두 원소를 비교하여 순서대로 되어 있지 않으면 교환한다.
-
1번 수행하고 나면 가장 큰 원소가 맨 뒤로 이동하게 된다. 2번째 수행에서는 맨 뒤에 있는 원소는 제외하고 수행한다.
-
시간복잡도 : O(n^2)
-
장점
- 구현이 쉽다.
- 이미 정렬된 데이터를 정렬할 때 가장 빠르다.
-
단점
- 느리다.
-
Code
public static void BubbleSort(int data[]) { int tmp; for (int i = data.length - 1; i >= 0; i--) { for (int j = 0; j < i; j++) { if (data[j] > data[j + 1]) { tmp = data[j]; data[j] = data[j + 1]; data[j + 1] = tmp; } } } }
4. Quick Sort
-
기준값(pivot)을 중심으로 왼쪽과 오른쪽으로 분할한다. 왼쪽 부분에는 기준값보다 작은 원소들, 오른쪽에는 기준값보다 큰 원소들을 이동시키며 정렬한다.
- 분할 : 정렬할 값들을 기준값을 중심으로 2개로 분할한다.
- 정복 : 기준값보다 작은 값은 왼쪽, 큰 값은 오른쪽으로 정렬한다. 부분집합의 크기가 1이하기 아니면 반복한다.
-
자바의
Arrays.sort()처럼 프로그래밍 언어 차원에서 기본적으로 지원되는 내장 정렬 함수는 대부분은 퀵 정렬을 기본으로 한다. -
일반적으로 원소의 개수가 적어질수록 나쁜 중간값이 선택될 확률이 높아지기 때문에, 원소의 개수에 따라 퀵 정렬에 다른 정렬을 혼합해서 쓴다.
-
시간복잡도 : pivot 값의 선택에 따라 다르다.
- 이상적인 경우(pivot 값을 기준으로 동일한 개수의 작은 값들과 큰 값들이 분할) : O(Nlog2N)
- 최악의 경우 (한 편으로 크게 치우치게 되면) : O(N^2)
-
Code
public static class QuickSort { public static void quickSort(int data[], int low, int high) { if (low >= high) { return; } int mid = partition(data, low, high); quickSort(data, low, mid - 1); quickSort(data, mid, high); } static int partition(int data[], int low, int high) { int pivot = data[(low + high) / 2]; while (low <= high) { while (data[low] < pivot) low++; while (data[high] > pivot) high--; if (low <= high) { swap(data, low, high); low++; high--; } } return low; } static void swap(int data[], int a, int b) { int tmp = data[a]; data[a] = data[b]; data[b] = tmp; } }
5. Merge Sort
-
여러 개의 정렬된 데이터들을 결합해 하나의 집합으로 만드는 정렬이다.
-
주어진 데이터가 하나 밖에 남지 않을 때까지 계속 둘로 쪼갠 후에 다시 크기 순으로 합치면서 정렬하는 것이다.
-
시간 복잡도 : O(nlogn)
-
공간 복잡도 : O(N)
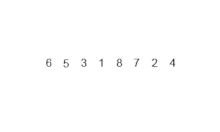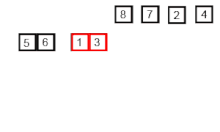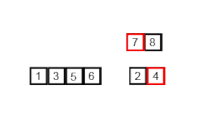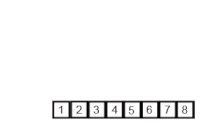
-
Code
public static class Merge { public static void mergeSort(int data[], int low, int high) { if (low >= high) { return; } int mid = (low + high) / 2; mergeSort(data, low, mid); mergeSort(data, mid + 1, high); merge(data, low, mid, high); } public static void merge(int data[], int low, int mid, int high) { int[] tmp = new int[data.length]; int l = low; // 첫 번째 부분집합의 시작 위치 int h = mid + 1; // 두 번째 부분집합의 시작 위치 int idx = low; // 배열 tmp 정렬된 원소를 저장할 인덱스 while (l <= mid && h <= high) { if (data[l] <= data[h]) { tmp[idx] = data[l]; l++; } else { tmp[idx] = data[h]; h++; } idx++; } if (l > mid) { for (int i = h; i <= high; i++, idx++) { tmp[idx] = data[i]; } } else { for (int i = l; i <= mid; i++, idx++) { tmp[idx] = data[i]; } } for (int i = low; i <= high; i++) { data[i] = tmp[i]; } } } -
헷갈렸던 점
-
mergeSort(data, low, mid); mergeSort(data, mid + 1, high); merge(data, low, mid, high); -
위와 같은 순서로 했을 때 아래와 같이 어떻게 저렇게 합쳐질 수 있을지 헷갈렸다.
-
배열 참초형 변수이기 때문에 Call by reference 효과를 내기 때문이다.
- 자바는 기본형 타입 변수와 참조형 타입 변수가 있는데 둘다 call by value 방식이다. 하지만 기본형은 그 값을 복사해서 주지만, 참조형 타입은 값의 래퍼런스(주소)가 저장되는 것이므로 그 값의 래퍼런스가 복사되어진다.
-

6. Heap Sort
-
완전 이진 트리를 기반으로 하는 힙 자료구조를 사용한 정렬 방법이다.
- 최대힙과 최소힙이 있다.
-
최대 힙을 구성한다고 할 때 현재 힙의 루트는 가장 큰 값이 존재한다(최대 힙 조건). 루트를 제거하고 마지막 노드를 루트로 올린 후 최대힙 조건에 맞게 힙을 만든다. 이렇게 되면 힙의 사이즈는 하나 준다. 이 과정을 힙의 사이즈가 1보다 클 때까지만 반복한다.
-
시간복잡도 : O(nlogn)
-
Code
public static class HeapSort { private static void heapify(int arr[], int length, int i) { int left = 2 * i + 1; int right = 2 * i + 2; int temp, largest = i; if (left < length && arr[left] > arr[largest]) { largest = left; } if (right < length && arr[right] > arr[largest]) { largest = right; } if (largest != i) { temp = arr[i]; arr[i] = arr[largest]; arr[largest] = temp; heapify(arr, length, largest); } } private static void heapSort(int arr[]) { int i, temp; int length = arr.length; for (i = length / 2 - 1; i >= 0; i--) { heapify(arr, length, i); } for (i = length - 1; i >= 0; i--) { temp = arr[0]; arr[0] = arr[i]; arr[i] = temp; heapify(arr, i, 0); } } }
7. Radix Sort (기수 정렬)
-
낮은 자리수부터 비교하여 정렬하는 것이다.
-
비교 연산을 하지 않아서 정렬 속도가 빠르다.
-
데이터 전체 크기에 기수 테이블의 크기만한 메모리가 더 필요하다.
-
정렬 방식
- 0~9까지의 Bucket(Queue 사용)을 준비한다.
- 모든 데이터에 대해 가장 낮은 자리수에 해당하는 Bucket에 차례대로 데이터를 넣는다.
- 0부터 Bucket에서 데이터를 가져온다.
- 가장 높은 자리수를 기준으로 하여 자리수를 높여가며 반복한다.
-
시간복잡도 : O(dn)
-
Code
public static class RadixSort { public static void radixSort(int[] data) { int maxSize = getMaxSize(data); ArrayList<Queue> bucket = new ArrayList<>(); int powed = 1; for(int i=0;i<10;i++) { bucket.add(new LinkedList()); } for(int i=0;i<maxSize;i++){ for(int j=0;j<data.length;j++){ //각 자리수에 맞는 인덱스의 버킷에 넣는다. bucket.get((data[j]/powed)%10).offer(data[j]); } //버킷에서 뺀다. for(int j=0, idx=0;j<data.length;){ while(!bucket.get(idx).isEmpty()){ data[j++] = (int) bucket.get(idx).poll(); } idx++; } powed *=10; } } public static int getMaxSize(int[] arr) { int maxSize = 0; for (int i = 0; i < arr.length; i++) { int tmp = (int) Math.log10(arr[i]) + 1; if (tmp > maxSize) maxSize = tmp; } return maxSize; } }
시간복잡도 비교

'Algorithm > Basic' 카테고리의 다른 글
| [알고리즘] Backtracking (백 트래킹) (0) | 2020.01.16 |
|---|---|
| [알고리즘] 최단 경로 정리 (0) | 2019.10.24 |
| [알고리즘] 깊이 우선 탐색(DFS : Depth-First Search) (0) | 2019.10.01 |
| [알고리즘] 동적 계획법 (Dynamic Programming) (0) | 2019.09.24 |
- Total
- Today
- Yesterday
- 우선순위큐
- 백트래킹
- N-Queen
- 사회망서비스
- 프로세스 스케줄링
- 백 트래킹
- 4-way-handshake
- SRTN
- loss function
- 자료구조
- 농협정보시스템IT
- binarySearch
- hashtable
- 네트워크
- MLQ
- hash
- DFS
- java
- 알고리즘
- 3-way-handshake
- 기능개발
- SWExpert
- Android
- programmers
- MFQ
- Process Scheduling
- 프로그래머스
- git
- Objective function
- algorithm
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |